By Paul Edge and David Seelmann, Corporate Risk Management, EDP
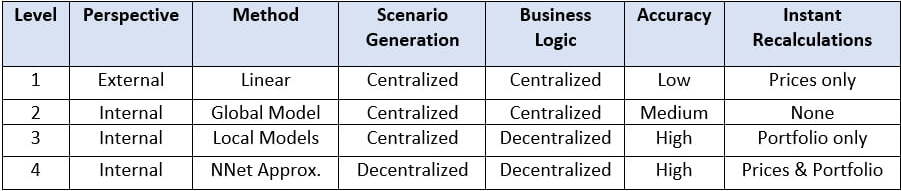
Cashflow risk models (CFRM) are used to project company performance and estimate the multi-year probabilities of key events occurring, such as financial ratios hitting certain trigger levels. This article compares various architectures for modelling such cashflows, from simple to the state of the art.
At the most basic level a CFRM can be created using only public information. Informed experts can create approximations of a company’s Business Logic (BL) and use publicly available prices of raw materials combined with estimates of production volumes to project a company’s future results. This exercise is useful not only for a single company but also for modelling close competitors. Models can be updated whenever new company accounts are published.
This basic approach informs peer comparisons and enhances short/long trading strategies made on a sector basis. It also enables shareholder level hedging strategies (e.g., mitigating an FX position resulting from a company’s natural business), allowing company performance to be isolated from macroeconomic effects.
Here, a person or central department is tasked with creating the CFRM using not only internal knowledge of the BL of each Business Unit (BU) and volume projections but also external knowledge of input prices. This requires experts not only in the inner workings of the business, but also people skilled in the generation of (say 10,000) realistic future economic scenarios used for Monte Carlo calculation which, although usually fast, is not considered to be instantaneous. The result is a centralized, high level company model where some non-linear BL effects may be captured, but calculations are still approximations. Models are refreshed on a regular basis (e.g., annually along with the planning cycle). At this level, broad overall risk can be measured, and basic hedging can be tested, leading to the discovery of high-level operational optimizations (e.g., tax) and efficiencies (e.g., insurance reduction) where internal BL knowledge produces an improved model in comparison to the External Perspective (Level 1).
The result is a centralized, high level company model where some non-linear BL effects may be captured, but calculations are still approximations.
At this level, economic scenarios are generated centrally by experts but there are several individual models managed locally by each BU. In essence, each BU is tasked with implementing what amounts to a small scale CFRM.This approach captures a higher detail of potential business impacts and edge cases. Based on the centralized projections for economic scenarios, the BUs return only their cashflows for each scenario/year to the central department. Company-wide agreement is needed over which variables will be modelled centrally and which will be added by BUs. For example, input prices of common goods can be derived from centrally produced macroeconomic variables, but production volumes are dependent on BU actions and should be generated at BU level. If the portfolio risk perspective is not needed then economic variables can be locally generated, allowing ad-hoc, BU specific requests to be quickly processed. One advantage of this approach is that expert economic knowledge is centralized, while BL knowledge is decentralized, ensuring a fully detailed model of the entire business. But the main benefit is that after BUs have returned their results, the only calculations remaining are a few vector additions. This allows individual projects to be quickly added or removed from the company portfolio without the need for a global recalculation. Hedges of any payoff complexity can be simultaneously and rapidly evaluated. The disadvantage is that key input variable properties such as means, volatilities and correlations of input prices are “baked into” the economic scenarios, so any changes to the economic scenarios require all BUs to rerun their model and return the results. Refreshing the full model requires a large, coordinated effort by many people across the organization.
Based on the centralized projections for economic scenarios, the BUs return only their cashflows for each scenario/year to the central department.
In the fully decentralized modelling approach, each BU sends a trained Neural network (NNet) approximation of their own CFRM to the central department, rather than a vector of cash-flow values. These individual NNets, which encode BL of the respective BU, can be easily aggregated into a company wide CFRM, which is then shared with all BUs. Individual model retraining is needed only when the BL of a BU changes significantly, which may be at separate times for different BUs. Since economic variables and production volumes are generated separately from the NNets (using any desired method), this allows the company wide CFRM to be run both centrally and locally by the BUs, simultaneously satisfying many business needs:
Training data for a NNet is created by populating CFRM inputs with random numbers, and no economic structure to these numbers is needed (one could even use a Latin hypercube). Model training is simple enough to be performed locally, although a shared vocabulary/taxonomy for labeling variables is still essential for coherent modelling. As NNets are better at interpolating than extrapolating, it is important to ensure that the entire range of values covered by the training data inputs is wider than the realistic economic inputs that may be asked of the model.